記述統計学
Descriptive Statistics
手元にあるデータを要約して、そのデータの特徴を記述する統計(学)のことです。
データの要約とは、データについて、次のような値を求めたり、グラフを描くことで、データが表わす傾向を探ります。
記述統計学に対して、推測統計学もあります。
- 代表値 (Representative Value)
- 平均値 (Average、Mean) → 単純平均値
- 中央値
- 最頻値
- 最大値
- 最小値
- 散布度 (Dispersion)
- 範囲(レンジ)
- 分散
- 標準偏差
- 四分位数
- 歪度
- 尖度
……など
これらの値を総称して、基本統計量(Basic Statistics)とか記述統計量(Descriptive Statistics)、要約統計量(Summary Statistics)と呼びます。
Excelでは「データ分析」メニューから「基本統計量」で求めることもできます。
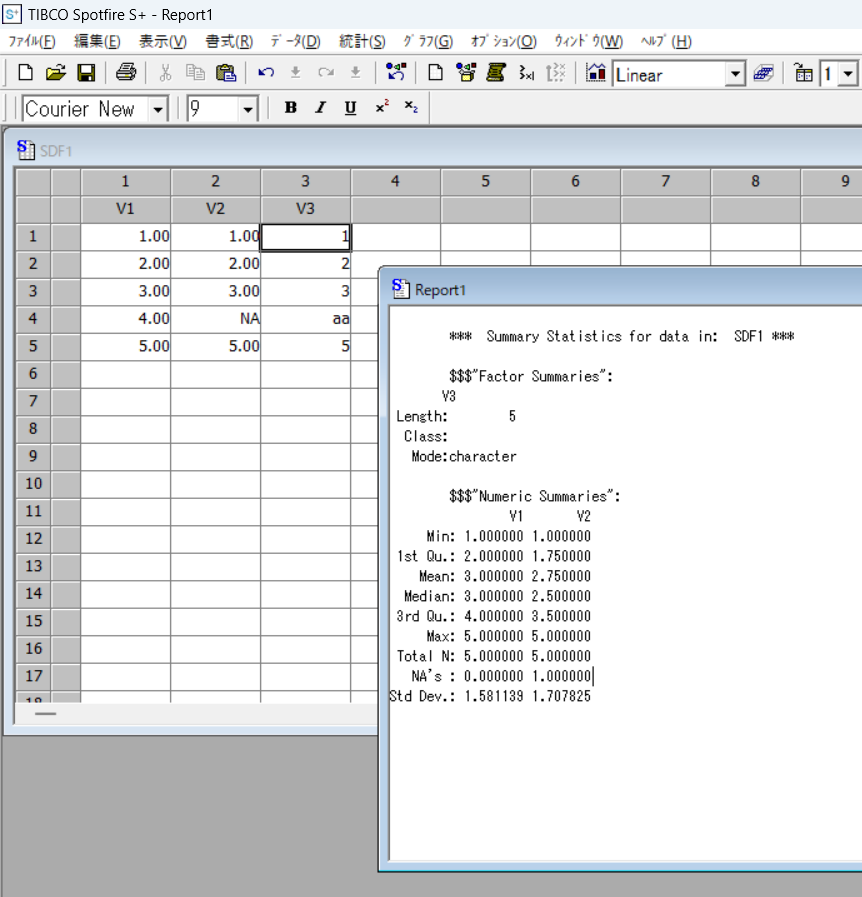
Rではsummaryコマンドで最小値・第一四分位数・中央値・単純平均値・第三四分位数・最大値を出力します。
「psych」パッケージをRにインストールすることで、describeコマンドで、データの個数、単純平均値、不偏標準偏差、中央値、トリム平均、中央絶対偏差、最小値、最大値、レンジ、歪度、尖度、標準誤差 を表示します。
data_cは名義尺度のデータ(カテゴリーデータ)のため、データ個数は5個として扱っているため要注意であることを示しています。
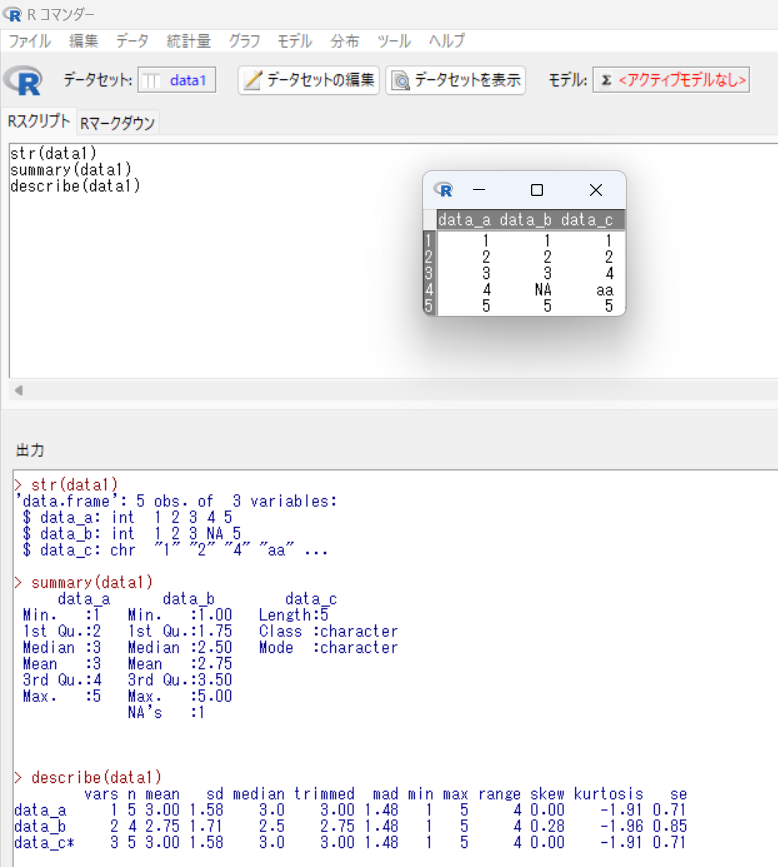
S-PLUSでは、「統計(S)」→「データサマリー(D)」→「統計量(S)」で、最小値、第一四分位数、単純平均値、中央値、第三四分位数、最大値、データ個数、欠損値の個数、不偏標準偏差を出力します。
出力の対象に、カテゴリーデータ(data_c)は含まれません。