記述統計学
手元にあるデータを要約して、そのデータの特徴を記述する統計(学)のことです。英語ではDescriptive Statistics。
データの要約とは、データについて、次のような値を求めたり、グラフを描くことで、データが表わす傾向を探ります。
記述統計学に対して、推測統計学もあります。
- 代表値 (Representative Value)
- 平均値 (Average、Mean) → 単純平均値
- 中央値
- 最頻値
- 最大値
- 最小値
- 散布度 (Dispersion)
- 範囲(レンジ)
- 分散
- 標準偏差
- 四分位数
- 歪度
- 尖度
……など
これらの値を総称して、基本統計量(Basic Statistics)とか記述統計量(Descriptive Statistics)、要約統計量(Summary Statistics)と呼びます。
Excel「データ分析」ツール「基本統計量」で求める方法
Excelでは「データ分析」メニューから「基本統計量」で求めることもできます。
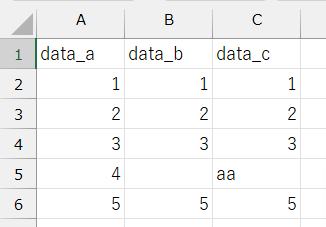
なおExcelでは「data_c」のように文字列が含まれていると、正常に出力できません。「data_a」のように、数値のみのデータを用意しましょう。
「データ」タブ → 「分析」グループの「データ分析」メニューから、「基本統計量」のメニューを選択します。
- 入力範囲(I): 基本統計量を出力したいデータの範囲を選択します。適切にデータが入力・配置されているのであれば、一度に複数の変数(列)を指定して、複数の基本統計量を出力することもできます。
- データ方向: ↓列方向(C)、→行方向(R)
- 先頭行をラベルとして使用(L): 先頭行をデータラベル(変数名)とする場合は、チェックを入れます。
先頭行にラベルが無い状態だと、出力ラベルには「列1」、「列2」……と表示されます。 - 出力オプション: 任意の出力先を指定します。
- 統計情報(S): 基本統計量を出力します。
- 平均の信頼度の出力(N): 母集団の平均値が収まる範囲を指定します。初期値は95%とします。
なおExcelの仕様により、出力結果は平均値を境に片側だけの範囲を表示します(本来信頼区間は、平均値を中心に両側の範囲を指すものです)。 - K番目に大きな値(A): 降順で何番目のデータを抽出して表示するかを1つ指定します。
- K番目に小さな値(M): 昇順で何番目のデータを抽出して表示するかを1つ指定します。
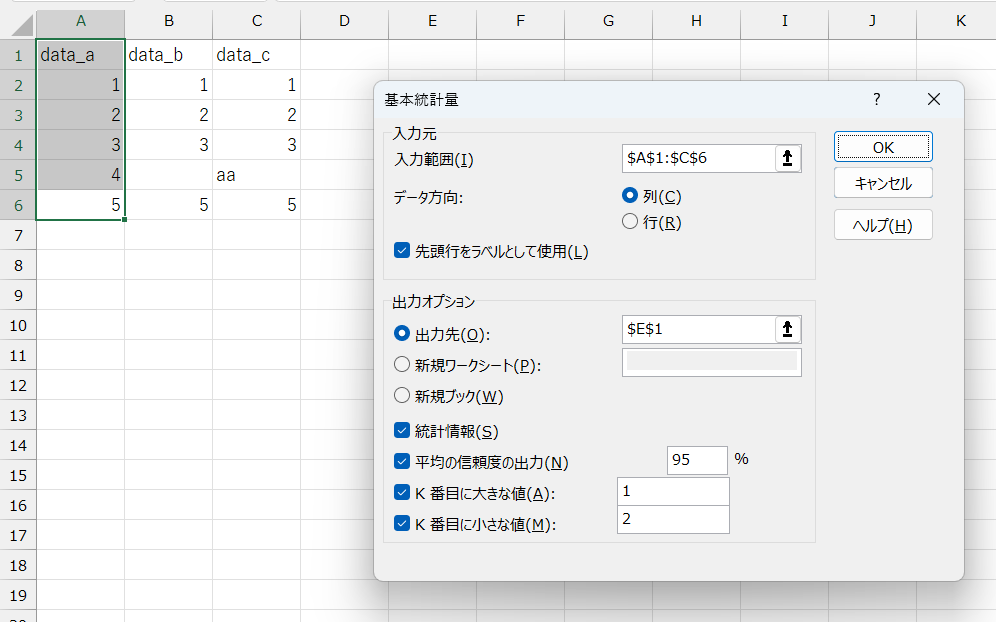
「data_a」については、Excelでは次のように表示されます。
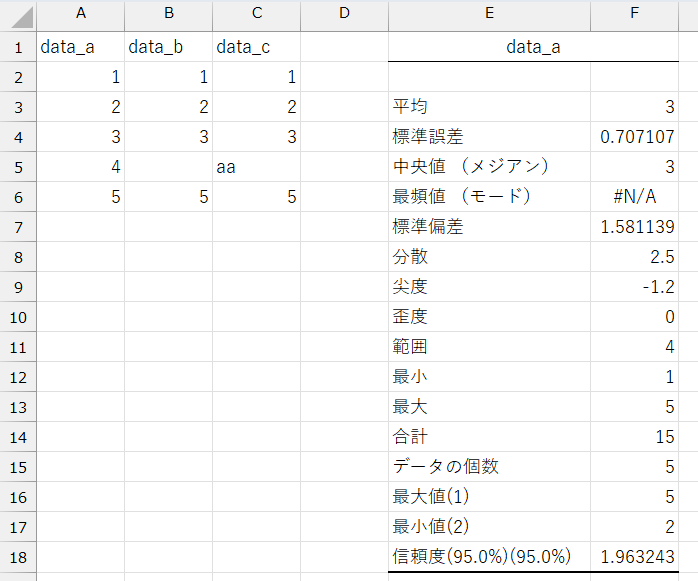
上から:
- 平均: 単純平均値 (AVERAGE関数)
- 標準誤差: 標本の平均値を基に、母集団の平均値が収まる範囲の推定。
「不偏標準偏差」÷「データの個数の平方根」または「不偏分散 ÷ データの個数」の平方根 - 中央値: MEDIAN関数
- 最頻値: MODE.SNGL関数(MODE.MULT関数によって複数の最頻値を見つけるデータの場合でも、1つしか出力されません)
- 標準偏差: 不偏標準偏差(STDEV.S関数)
- 分散: 不偏分散(VAR.S関数)
- 尖度(せんど): 正規分布と比べての尖り具合(KURT関数)
正=正規分布よりも尖っている、負=正規分布よりも尖り度合いが緩い - 歪度(わいど): 正規分布と比べての偏り具合(SKEW関数)
正=正規分布と比べて中心よりも左側に偏っている、負=正規分布と比べて中心よりも右側に偏っている - 範囲: データのレンジ。最大値(MAX関数)から最小値(MIN関数)の差
- 最小: MIN関数
- 最大: MAX関数
- 合計: SUM関数
- データの個数: COUNT関数(※ 古いバージョンでは「標本数」という表示もありました。本来は「サンプルサイズ」や「標本の大きさ」と呼びます)
- 最大値: カッコ内は指定した順位。LARGE関数。(※ 「K番目に大きな値」を指定した場合のみ)
- 最小値: カッコ内は指定した順位。SMALL関数(※ 「K番目に小さな値」を指定した場合のみ)
- 信頼度: CONFIDENCE.T関数……信頼区間の片側を出力(Excelの仕様:両側ではないことに注意!)
「t分布の両側確率(T.INV.2T関数) × 標準誤差」(※ 「平均の信頼度の出力」を指定した場合のみ。0.95以外を選んだ場合は、項目名に「信頼度(95.0%)(90.0%)」のように表示され、後者の確率を基に出力されます)
Rで主な基本統計量を求める方法
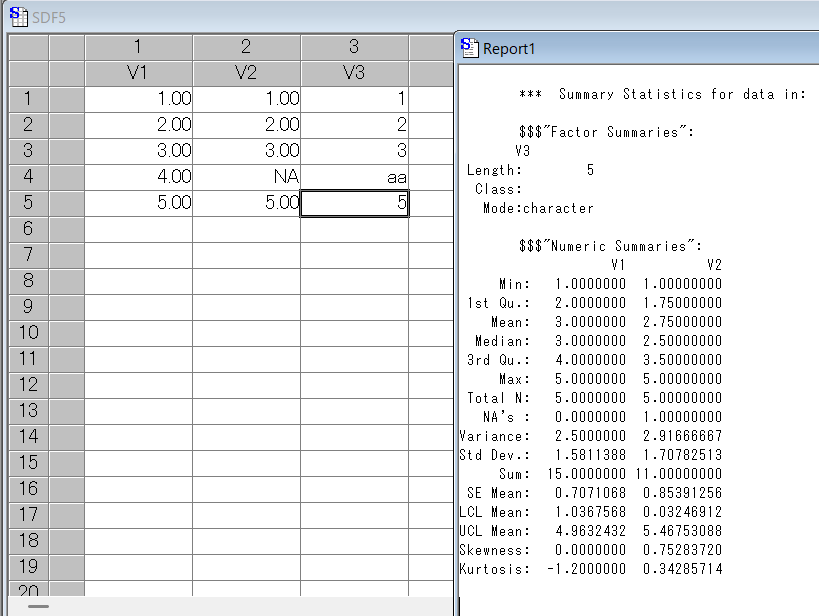
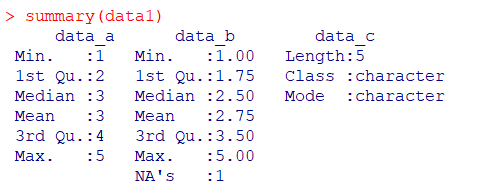
R ではdata_a、data_b、data_cを「data1」というデータセットとして、summaryコマンドで左から順に、最小値、第一四分位数、中央値、単純平均値、第三四分位数、最大値、欠損値の個数を出力しています。
data_cは文字列のデータとして認識されています。
R Commander(Rcmdr)パッケージでは、data_a、data_bを「data1」というデータセットとして、numSummaryコマンドで左から順に、単純平均値、不偏標準偏差、標準誤差、不偏分散、四分位範囲(第三四分位数 - 第一四分位数)、変動係数(不偏標準偏差 ÷ 単純平均値)、歪度、尖度(*Type2)、0パーセンタイル(最小値)、25パーセンタイル、50パーセンタイル(中央値)、75パーセンタイル、100パーセンタイル(最大値)、データの個数、欠損値の個数を出力しています。
*Type2: Excelなどで採用している計算方法

S-PLUSでは、「統計(S)」→「データサマリー(D)」→「統計量(S)」で、最小値、第一四分位数、単純平均値、中央値、第三四分位数、最大値、データ個数、欠損値の個数、不偏分散、不偏標準偏差、合計、標準誤差、信頼区間(ここでは0.95)の下限、上限、歪度、尖度を出力しています。
出力の対象に、data_c(カテゴリーデータ)は含まれていません。
歪度・尖度はExcelと同様の式(Type2)を採用しています。